



Java : Set(セット)の基本
Set は、Java コレクション・フレームワークの1つです。
重複のない複数の要素を管理します。
大量の要素を追加しても、基本操作である add や remove, contains のパフォーマンス低下が起こらないのが特徴です。
本記事では、そんな Set の基本的な使い方を解説していきます。
概要
重複要素のないコレクションです。
すなわち、セットは、e1.equals(e2)であるe1とe2の要素ペアは持たず、null要素を最大1つしか持ちません。

Set は、List や配列のように複数の値を管理できます。
この値のことを 要素 とも呼びます。
List や 配列 との違いは、要素の順序を基本的に管理しないことです。(要素の順序を管理するSet実装もあります)
要素と要素とのつながりはなく、バラバラに持っているイメージです。

Set に要素を大量に追加
↓
指定した要素が含まれているか高速に確認
というのが基本的な流れになります。
そんな Setインタフェースには3つの大きな特徴があります。
- 要素の重複はできません。
- (基本的には) 要素の順序は保持されません。
- 大量の要素が追加されても、基本操作(add, remove, containsなど)は高速です。
基本操作
Set の生成
それでは、Set の基本的な使い方をコード例で見ていきましょう。
final Set<String> set = new HashSet<>();
System.out.println(set); // []
System.out.println(set.size()); // 0
まずは Set を生成します。
final Set<String> set = new HashSet<>();
^^^^^^^^^^^^^^^
今回は、Set の実装には HashSet を使います。(HashSet については後述します)
final Set<String> set = new HashSet<>();
^^^^^^
Set には型パラメータが1つ必要です。
Set<E>の型パラメータには、
- E : 要素の型
を指定します。
今回は String を指定しました。
(もちろん、数値を使いたい場合は Integer を指定することもできます)
System.out.println(set); // []
System.out.println(set.size()); // 0
Set にはまだ要素がないので、空である [] が表示されます。
サイズも 0 になります。
要素の追加
boolean add(E e)
指定された要素がセット内になかった場合、セットに追加します(オプションの操作)。
要素を1つ追加するには add メソッドを使います。
final Set<String> set = new HashSet<>();
System.out.println(set); // []
System.out.println(set.size()); // 0
set.add("aaa");
System.out.println(set); // [aaa]
System.out.println(set.size()); // 1
set.add("bbb");
System.out.println(set); // [aaa, bbb]
System.out.println(set.size()); // 2
set.add("ccc");
System.out.println(set); // [aaa, ccc, bbb]
System.out.println(set.size()); // 3
add するたびに、Set に要素が追加されていきます。
サイズも増えていきます。
System.out.println(set); // [aaa, ccc, bbb]
^^^ ^^^ ^^^
注意点としては、HashSet の要素の順番は、要素が追加された順番になるとは限りません。
List とは違う点ですね。
要素が含まれているか確認
boolean contains(Object o)
指定された要素がこのセットに含まれている場合にtrueを返します。
指定した要素が含まれているか確認するには contains メソッドを使います。
final Set<String> set = new HashSet<>();
set.add("aaa");
set.add("bbb");
set.add("ccc");
System.out.println(set); // [aaa, ccc, bbb]
System.out.println(set.contains("aaa")); // true
System.out.println(set.contains("bbb")); // true
System.out.println(set.contains("ccc")); // true
System.out.println(set.contains("xxx")); // false
要素が含まれていれば true、含まれていなければ false になります。
要素の削除
要素を削除するには remove メソッドを使います。
final Set<String> set = new HashSet<>();
set.add("aaa");
set.add("bbb");
set.add("ccc");
System.out.println(set); // [aaa, ccc, bbb]
System.out.println(set.size()); // 3
set.remove("ccc");
System.out.println(set); // [aaa, bbb]
System.out.println(set.size()); // 2
set.remove("aaa");
System.out.println(set); // [bbb]
System.out.println(set.size()); // 1
set.remove("bbb");
System.out.println(set); // []
System.out.println(set.size()); // 0
すべての要素を取得
Set は Iterableインタフェース を継承しています。
そのため、拡張for文ですべての要素を取得することができます。
final Set<String> set = new HashSet<>();
set.add("aaa");
set.add("bbb");
set.add("ccc");
System.out.println(set); // [aaa, ccc, bbb]
System.out.println("--- 拡張for文 ---");
for (final var element : set) {
System.out.println(element);
}
// 結果
// ↓
//--- 拡張for文 ---
//aaa
//ccc
//bbb
その他のメソッド
他にも、Setインタフェースには、
- セットが空か判定 : isEmpty
- 要素を一度に追加 : addAll
- すべての要素を削除 : clear
などなど、便利なメソッドがあります。
もう少し詳しく知りたい方は「Java : Set (セット) - API使用例」の記事もご参照ください。
代表的なSetの実装
標準API には、Set の実装がいくつか用意されています。
用途に合わせて Set の実装を使い分けると、プログラムのパフォーマンスが向上します。
ここでは、よく使われる代表的な実装をご紹介します。
| API | 簡単な説明 | 要素の順序の保持 | 変更可能 | null要素を許容 |
|---|---|---|---|---|
| HashSet | もっとも基本となるSetの実装です。 | × | 〇 | 〇 |
| LinkedHashSet | HashSetに順序の保持を追加した実装です。 | 〇 (要素の追加した順序が保持されます) | 〇 | 〇 |
| TreeSet | 要素を常にソートした順序に保持する実装です。 | 〇 (ソートされた順序が保持されます) | 〇 | × |
| Set.of | 変更不可能なSetを返します。 | × | × | × |
HashSet
このクラスは、ハッシュ表(実際にはHashMapのインスタンス)に連動し、Setインタフェースを実装します。 このクラスでは、セットの反復順序について保証しません。特に、その順序を一定に保つことを保証しません。
...
このクラスは、ハッシュ関数が複数のバケットで適切に要素を分散することを前提として、基本のオペレーション(add、remove、contains、およびsize)で一定時間の性能を提供します。
HashSet は、Set のもっとも基本となる実装です。
Object.hashCode でハッシュ表を作ることによって、Set の要素数が多くなっても基本操作(add, remove, contains)の性能は落ちません。
比較として List では要素数が多くなればなるほど、(末尾以外の)add や remove、contains の性能は落ちていきます。
final var set = new HashSet<String>();
set.add("aaa");
set.add("bbb");
set.add("ccc");
set.add("ddd");
System.out.println(set); // [aaa, ccc, bbb, ddd]
System.out.println(set.size()); // 4
ハッシュ表の仕組み
とても簡易的にしたハッシュ表の仕組みをご紹介します。
どうしてハッシュ表は高速なのか?というのがなんとなくイメージできればな、と。
※Java の HashSet や HashMap がこのような実装にはなっていないかもしれないのでご注意ください。(もう少し効率よくなっているとは思います)
ハッシュ表には、その名のとおりハッシュコードを使います。
Set では要素のハッシュを使います。
Object.hashCode の int だと範囲が広いので、今回は分かりやすく 0 ~ 99 の範囲のハッシュ値に変換します。
もちろん、ハッシュコードの範囲を狭くすることで衝突しやすくなります…が、そのあたりは今回は考えないことにします。
// 追加する要素を4つ用意します。
final var elements = List.of("aaa", "bbb", "ccc", "ddd");
// それぞれのハッシュコード
for (final var element : elements) {
//aaa : hashCode = 96321
//bbb : hashCode = 97314
//ccc : hashCode = 98307
//ddd : hashCode = 99300
System.out.println(element + " : hashCode = " + element.hashCode());
}
// ハッシュコードの範囲を0~99にします。
for (final var element : elements) {
//aaa : hashCode = 21
//bbb : hashCode = 14
//ccc : hashCode = 7
//ddd : hashCode = 0
System.out.println(element + " : hashCode = " + Math.abs((element.hashCode() % 100)));
}
ハッシュコードは 0~99 の範囲となるので、ハッシュ表にはサイズ100の配列を用意します。
そして、Set.add で要素を追加するときに、
- 要素のハッシュコード(0~99)を計算
- 配列のインデックス(添え字)に、1. で計算したハッシュコードを使う
- 配列[要素のハッシュコード] に、要素を格納
という処理をします。
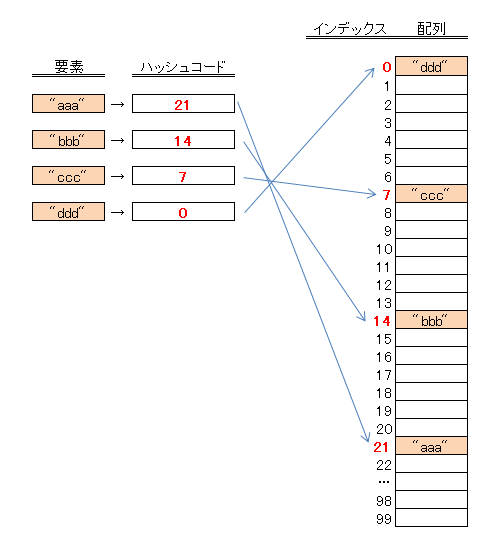
add, remove, contains は、単純な配列へのインデックス参照となるので、高速になる、というのはイメージできますでしょうか。
その代わり、サイズ100の配列を作ったのに使われているのは4箇所だけです。残りの96箇所は無駄になっていますね。
メモリは余計に使うけど、処理速度を優先させたもの…それがハッシュ表です。
もちろん、実際の実装はもっと効率良くなっているはずです。
ハッシュコードが衝突することも考慮されています。
本記事では、そのあたりの難しいところは割愛します。
LinkedHashSet
予測可能な反復順序を持つSetインタフェースのハッシュ表とリンク・リストの実装です。 この実装は、すべてのエントリをまたがる二重のリンク・リストを保持するという点で、HashSetとは異なります。 このリンク・リストは、反復順序を定義します。この順序は、要素がセットに挿入された順序です(挿入順)。
Set は基本的に要素の順序を保持しません。
しかし、LinkedHashSet は順序を保持する Set です。
// LinkedHashSetの例
final var linkedHashSet = new LinkedHashSet<String>();
linkedHashSet.add("aaa");
linkedHashSet.add("bbb");
linkedHashSet.add("ccc");
linkedHashSet.add("ddd");
// 要素の順番は、要素が追加された順になります。
System.out.println(linkedHashSet); // [aaa, bbb, ccc, ddd]
// HashSetの例
final var hashSet = new HashSet<String>();
hashSet.add("aaa");
hashSet.add("bbb");
hashSet.add("ccc");
hashSet.add("ddd");
System.out.println(hashSet); // [aaa, ccc, bbb, ddd]
TreeSet
TreeMapに基づくNavigableSet実装です。 要素の順序付けは、自然順序付けを使って行われるか、セット構築時に提供されるComparatorを使って行われます。
TreeSet は、要素の並び順を、
- 要素の自然順序
- もしくは指定した Comparator
で常にソートしてくれる Set です。
final var set = new TreeSet<String>();
set.add("ccc");
set.add("ddd");
set.add("bbb");
set.add("aaa");
System.out.println(set); // [aaa, bbb, ccc, ddd]
System.out.println(set.size()); // 4
Set.of
static <E> Set<E> of(E... elements)
任意の数の要素を含む変更不可能な集合を返します。
Set.of は 変更不可能(イミュータブル) な Set を返します。
Set を変更するメソッド(add や remove など)を使うと、非チェック例外の UnsupportedOperationException が発生します。
final var set = Set.of("aaa", "bbb", "ccc", "ddd");
System.out.println(set); // [ddd, aaa, bbb, ccc]
System.out.println(set.size()); // 4
//set.add("eee"); // UnsupportedOperationException発生
//set.remove("aaa"); // UnsupportedOperationException発生
独自クラスを要素にする
独自クラスを Set の要素に指定したい場合は、その独自クラスの hashCode と equals メソッドを正しくオーバーライドしましょう。
hashCode と equals メソッドのオーバーライドについては、
の記事でも解説していますので、そちらもご参照ください。
コード例になります。
public class Sample {
private final String text;
private final int value;
public Sample(String text, int value) {
this.text = text;
this.value = value;
}
public String getText() {
return text;
}
public int getValue() {
return value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Sample sample = (Sample) o;
return value == sample.value && Objects.equals(text, sample.text);
}
@Override
public int hashCode() {
return Objects.hash(text, value);
}
@Override
public String toString() {
return "Sample[text=" + text + ", value=" + value + "]";
}
}
final var set = Set.of(new Sample("aaa", 1), new Sample("bbb", 2), new Sample("ccc", 3));
// [Sample[text=ccc, value=3], Sample[text=bbb, value=2], Sample[text=aaa, value=1]]
System.out.println(set);
もしくは、Java 16 以降を使っているのであれば、レコードクラスが便利です。
レコードクラスでは、面倒な hashCode と equals のオーバーライドを自動でしてくれます。
public record Sample(String text, int value) {
}
final var set = Set.of(new Sample("aaa", 1), new Sample("bbb", 2), new Sample("ccc", 3));
// [Sample[text=ccc, value=3], Sample[text=bbb, value=2], Sample[text=aaa, value=1]]
System.out.println(set);
非常にシンプルになりました。
レコードクラスについては
の記事も参考にしていただけたら幸いです。
まとめ
Setインタフェースには3つの大きな特徴があります。
- キーの重複はできません。
- (基本的には) 要素の順序は保持されません。
- 大量の要素が追加されても、基本操作(add, remove, containsなど)は高速です。
また、Setの主な実装には
- HashSet
- LinkedHashSet
- TreeSet
- Set.of
があります。
用途によってうまく使い分けるように心がけたいですね。
関連記事
- Object.hashCode (ハッシュ・コード) とは
- レコードクラスの基本 (Record Class)
- 不変オブジェクト(イミュータブル) とは
- List(リスト)の基本
- Map(マップ)の基本
- List の初期化方法いろいろ
- Map の初期化方法いろいろ
- Set の初期化方法いろいろ
- 配列 vs. List
- 配列からListへの変換
- List から配列への変換
- API 使用例
- Collection (コレクション)
- Collections (コレクション操作)
- Comparable
- Comparator
- Iterator
- List (リスト)
- Map (マップ)
- Map.Entry (キーと値のペア)
- Queue (キュー)
- AbstractQueue
- ArrayBlockingQueue (ブロッキング・配列キュー)
- ArrayDeque (両端キュー)
- BlockingDeque (ブロッキング・両端キュー)
- BlockingQueue (ブロッキング・キュー)
- ConcurrentLinkedDeque (並列処理用・両端キュー)
- ConcurrentLinkedQueue (並列処理用キュー)
- Deque (両端キュー)
- LinkedBlockingDeque (ブロッキング・リンク両端キュー)
- LinkedBlockingQueue (ブロッキング・リンクキュー)
- LinkedList (二重リンク・リスト)
- PriorityBlockingQueue (ブロッキング・優先度付きキュー)
- PriorityQueue (優先度付きキュー)
- RandomAccess
- Set (セット)
- Spliterator